Capítulo 2 Explorando factores sociales en el ausentismo electoral
Antenor Escudero
2.1 Introducción
En la entrega anterior del Taller de R Markdown, se realizó un breve estudio vinculando variables sociales del IDH con el ausentismo electoral en las Elecciones Complementarias del 2020, enfocado en el caso de los distritos de Lima. En dicho estudio se realizó una comparación entre el nivel de IDH y los indicadores que lo componen con el ausentismo electoral, encontrándose una relación positiva y fuerte con el PBI per capita y los años de estudios. Considerando ello, esta entrega busca ampliar dichos hallazgos, considerando densidad poblacional como variable en el ausentismo, así como ampliando la selección a nivel nacional de distritos.
2.2 Paquetes usados
Los paquetes utilizados son readxl, tidyverse, janitor, ggthemes y pobreza2018. El paquete readxl nos permite leer y manejar los documentos en formato .xslx, el paquete tidyverse nos da herramientas para el manejo y ordenamiento de datos; y el paquete janitor nos permite reorganizar los valores; el paquete ggthemes nos permite generar gráficos de diverso tipo y, finalmente, pobreza2018 nos permite acceder al ubigeo de la Reniec y convalidar con las demás tablas.
2.3 Conjuntos de datos usados
Se utilizarán los conjuntos de datos de las tablas de los resultados electorales de la primera y segunda vuelta de las elecciones del 2021, de Ronderos.pe; la tabla de información regional de Ceplan, la tabla del Indíce de Desarrollo Humano y la tabla de ubigeos.
La tabla de resultados electorales, Elecciones2021, nos proveerá del ubigeo, los votantes habilitados y cantidad de personas que votaron en primera y segunda vuelta, a partir de lo cual se calculará el porcentaje de ausentismo. La tabla de Ceplan,nos proveerá del ubigeo, la densidad poblacional, el porcentaje de desnutrición crónica, el índice de desarrollo humano, el porcentaje de población en pobreza y en pobreza extrema, la población ocupada y el presupuesto devengado per capita; renombrándose la tabla como CEPLAN. La tabla del índice de desarrollo humano 2019, IDH2019, nos proveera de la esperanza de vida al nacer, la población de 18 años con educación secundaria completa, el ingreso familiar per capita y el ubigeo. La tabla de ubigeos nos permite homogenizar los ubigeos de RENIEC e INEI.
Las tablas serán vinculadas mediante el ubigeo, resultando en la tabla Ausentismo2021 que agrupará estas variables y data.
Cargamos la tabla CEPLAN, escogiendo la hoja “Distrital,” usando “skip” para establecer el nombre de las columnas. Además, filtramos a través del código de ubigeo los casos distritales. Además, mediante select tomamos las columnas relevantes para nuestro estudio y modificamos sus nombres para facilitar su uso.
CEPLAN <-
read_excel("data/DATA_CEPLAN.xlsx", sheet = "Distrital", skip = 8) %>%
clean_names() %>%
filter(
str_detect(ubigeo, "^\\d{6}$"),
!str_detect(ubigeo, "^\\d{4}00$"),
ubigeo != "159999"
) %>%
select (
UBIGEO = ubigeo,
POBLACION2020 = poblacion_total_2020_1b,
DENSIPOB = densidad_2020,
PORCENDESCRONI = porcentaje_de_desnutricion_cronica_ninos_menores_de_5_anos_2020_9,
INDEHU2019 = indice_de_desarrollo_humano_idh_2019_15,
PORPOBPOBR = porcentaje_de_la_poblacion_en_pobreza_total_16a,
PORPOBPOBREX = porcentaje_de_la_poblacion_en_pobreza_extrema_17a,
POBOCU = poblacion_ocupada_2017_18,
DEVPERCAP2020 = devengado_per_capita_en_soles_2020_total_19
)Luego, cargamos los datos de IDH2019, utilizando skip=3 y clean_names para modificar los nombres de las columnas, seleccionando Ubigeo, Esperanza de vida al nacer, Población de 18 años con educación secundaria completa e Ingreso familiar per capita. Utilizamos filter para descartar los ubideos de provincias y regiones, quedándonos con distritos.
IDH2019 <- read_xlsx("data/IDHPERU2019.xlsx", skip = 3) %>%
clean_names() %>%
select(
UBIGEO = ubigeo,
ESPVIDNAC = esperanza_de_vida_al_nacer_7,
POB18SECOM = poblacion_18_anos_con_educ_secundaria_completa_8,
INGFAMCAP = ingreso_familiar_per_capita_10
) %>%
filter(
str_detect(UBIGEO, "^\\d{6}$"),
!str_detect(UBIGEO, "^\\d{4}00$"),
UBIGEO != "159999"
)Luego incluimos la tabla Elecciones2021. Debido a que la data se distribuye en las mesas de votación, las agrupamos mediante el código de ubigeo, sumando la cantidad de votantes hábiles y el total de ciudadanos que votaron de cada ubigeo en ambas vueltas, creando dos columnas producto de calcular el porcentaje de ausentismo en ambas vueltas. Además, filtramos los ubigeos no necesitados.
Elecciones2021 <- read_csv("data/presidencial.csv") %>%
select (
v2_CCODI_UBIGEO,
v1_TOT_CIUDADANOS_VOTARON,
v1_NNUME_HABILM,
v2_TOT_CIUDADANOS_VOTARON,
v2_NNUME_HABILM
) %>%
group_by(v2_CCODI_UBIGEO) %>%
summarise(
v1_TOT_CIUDADANOS_VOTARON = sum (v1_TOT_CIUDADANOS_VOTARON, na.rm = TRUE) ,
v1_NNUME_HABILM = sum (v1_NNUME_HABILM, na.rm = TRUE),
v2_NNUME_HABILM = sum (v2_NNUME_HABILM, na.rm = TRUE),
v2_TOT_CIUDADANOS_VOTARON = sum (v2_TOT_CIUDADANOS_VOTARON, na.rm = TRUE)
) %>%
mutate (
PORAUSENTEV1 = (1 - (v1_TOT_CIUDADANOS_VOTARON / v1_NNUME_HABILM)) * 100,
PORAUSENTEV2 = (1 - (v2_TOT_CIUDADANOS_VOTARON / v2_NNUME_HABILM)) * 100
) %>%
select (UBIGEO = v2_CCODI_UBIGEO, PORAUSENTEV1, PORAUSENTEV2) %>%
filter(!str_starts(UBIGEO, "9"))Después, creamos la tabla ubigeos seleccionando region, provincia, distrito y ubigeo, a fin de, mediante este último, estandarizar los códigos de ubigeo entre las tablas, que utilizan los códigos de RENIEC o de INEI.
ubigeos <- read_excel("data/equivalencia_ubigeos.xlsx")Por último, compilamos la información de las cuatro tablas y, con las variables escogidas, creamos la tabla Ausentismo2021, vinculándolas mediante ubigeo como variable común y articulándo a las filas.
Ausentismo2021<- ubigeos %>%
left_join (Elecciones2021, by = c("UBIGEO_RONDEROS" = "UBIGEO")) %>%
left_join(CEPLAN) %>%
left_join(IDH2019) %>%
mutate(across(-(region:UBIGEO), as.numeric)) %>%
mutate (PORPOBOCU = (POBOCU/POBLACION2020)*100)2.4 Resultados
A fin de iniciar el estudio de los datos, primero debemos encontrar la relación entre el ausentismo en ambas vueltas a fin de encontrar diferencias que puedan influenciar en el comportamiento de estas variables con otras.
Ausentismo2021 %>%
ggplot(aes(PORAUSENTEV1, PORAUSENTEV2)) +
geom_point()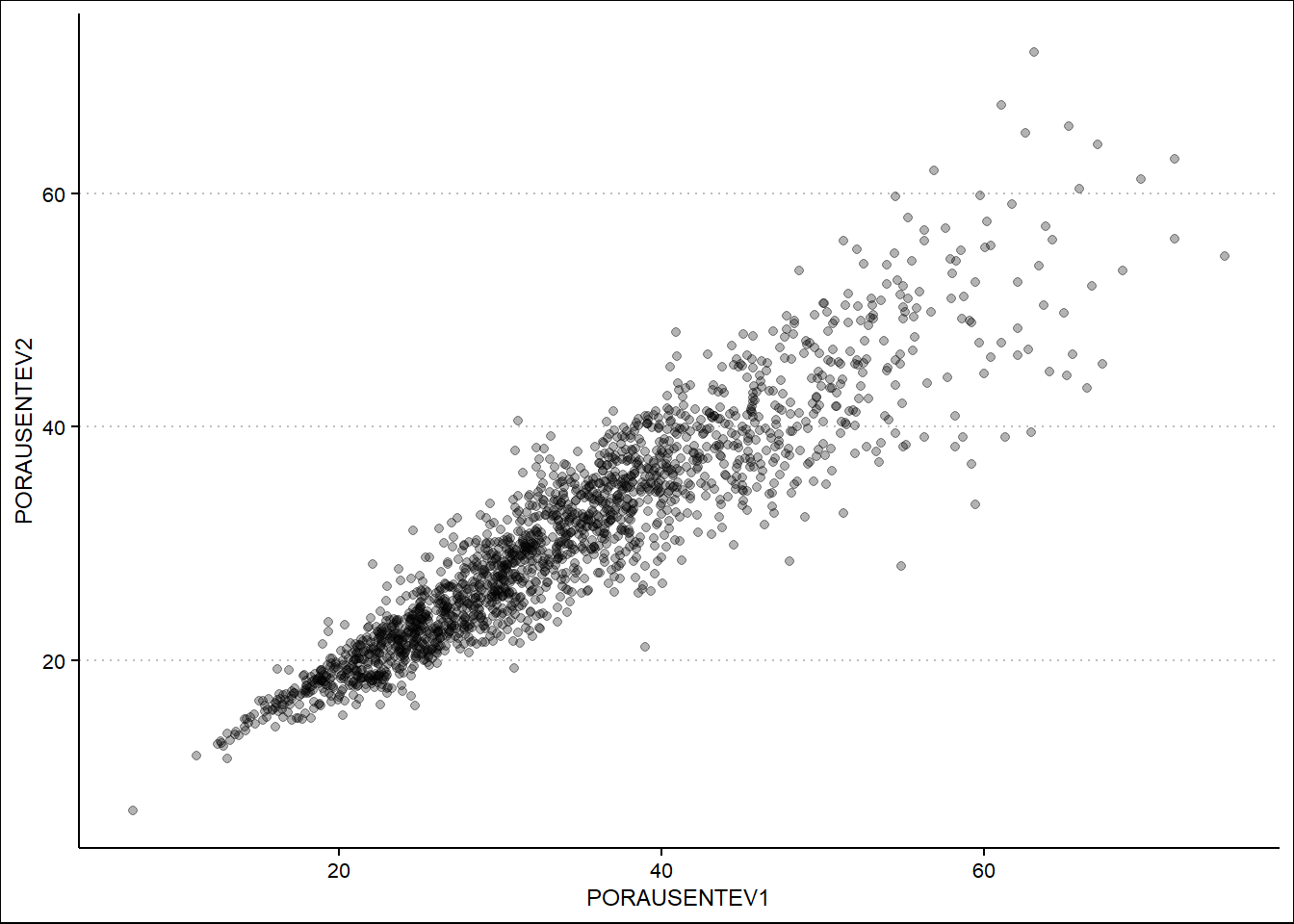
Como podemos observar, hay una relación directa entre ambas variables, por lo que usar ambas vueltas de forma diferente no tiene propósito; a fin de partir de la data más reciente, se utilizará el ausentismo de la Segunda Vuelta.
Procedemos a realizar el cruce de variables, tomando como variable independiente el Porcentaje de Ausentismo en Segunda vuelta y variables dependientes el IDH, la Esperanza de Vida al Nacer, el Porcentaje de Población Mayor de 18 años con Secundaria Completa, los Ingresos Familiares per Capita, el Presupuesto Devengado Total per Capita y los Porcentajes de Población en Situacion de Pobreza y Pobreza Extrema.
Para empezar, cruzamos el ausentismo con el IDH de los distritos.
Ausentismo2021 %>%
select(UBIGEO, INDEHU2019, PORAUSENTEV2) %>%
ggplot(aes(INDEHU2019, PORAUSENTEV2)) +
geom_point() +
labs(
title = "Relación entre IDH distrital y Ausentismo Electoral en la Primera Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "´Índice de Desarrollo Humano",
y = "Porcentaje de Ausentismo Electoral",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
)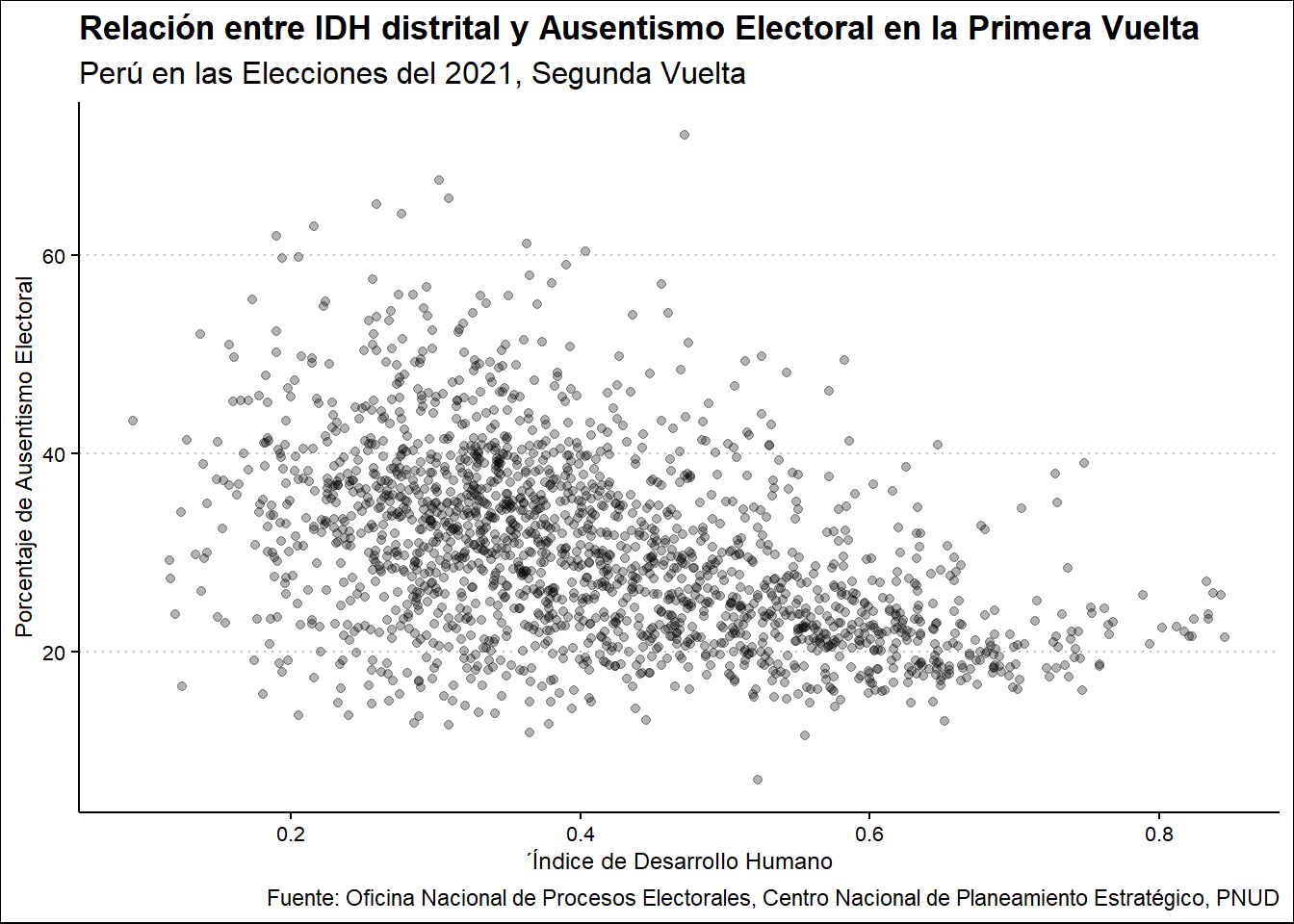
Tal como podemos observar, en los niveles bajos de IDH hay mucha dispersión lo que dificulta afirmar un mayor ausentismo, sin embargo, a medida que el nivel aumenta, hay un menor ausentismo, asi como una menor dispersión, aunque a cierto punto, la tendencia se revierte al elevarse mucho.
Procedemos a realizar la misma operación con Esperanza de Vida al Nacer.
Ausentismo2021 %>%
select(UBIGEO, ESPVIDNAC, PORAUSENTEV2) %>%
ggplot(aes(ESPVIDNAC, PORAUSENTEV2)) +
geom_point() +
labs(
title = "Relación entre Esperanza de Vida al Nacer y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Esperanza de Vida al Nacer",
y = "Porcentaje de Ausentismo Electoral",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
)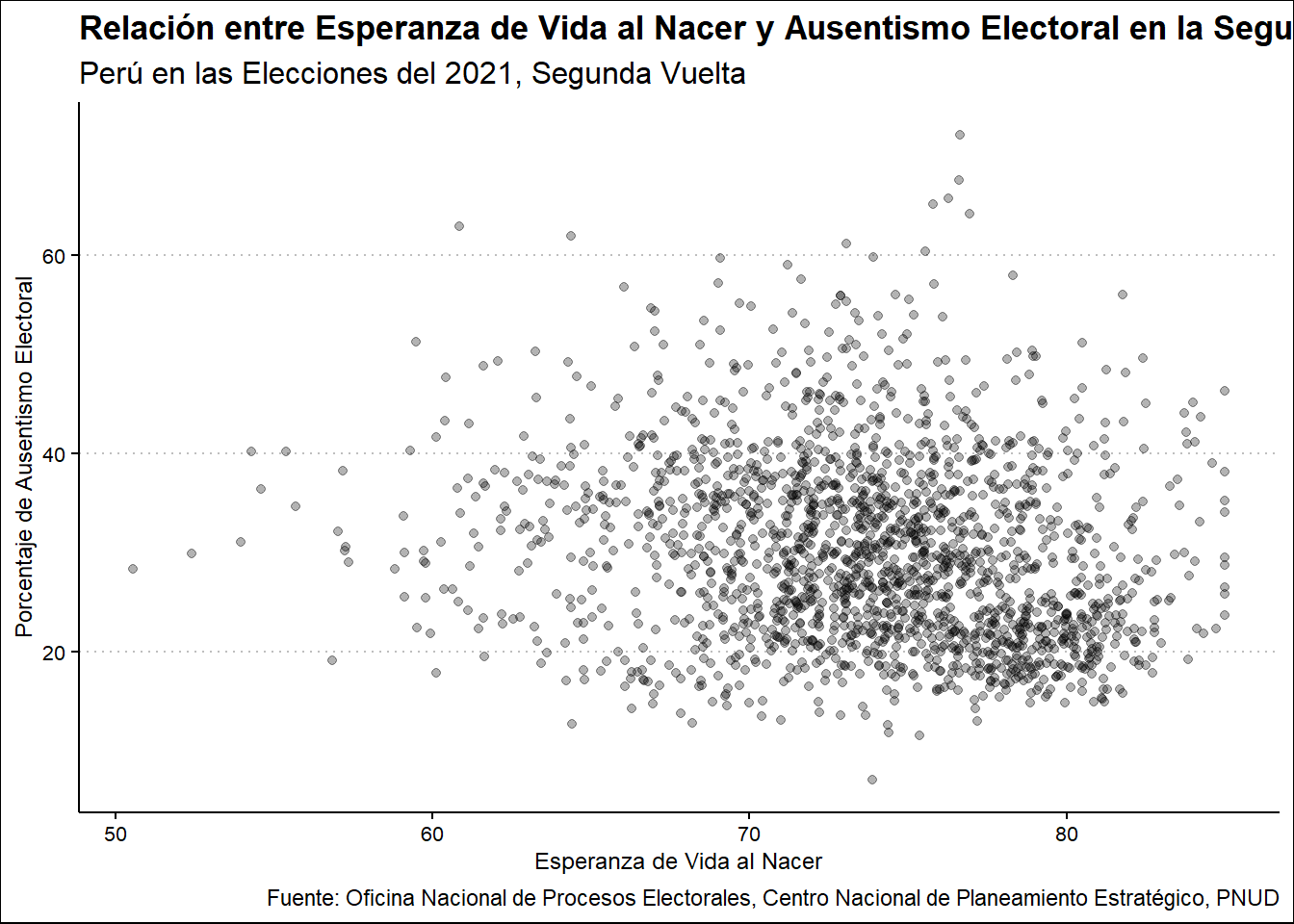
Hay una notoria dispersión en este caso entre el Porcentaje de Ausentismo y la Esperanza de Vida al Nacer, no puede afirmarse alguna relación definida.
En el caso de Densidad Poblacional, observamos esta tendencia.
Ausentismo2021 %>%
select(UBIGEO, DENSIPOB, PORAUSENTEV2) %>%
ggplot(aes(DENSIPOB, PORAUSENTEV2)) +
scale_x_log10(breaks = c(1, 10, 100, 1000, 10000)) +
geom_point() +
labs(
title = "Relación entre Densidad Poblacional Distrital y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Densidad Poblacional",
y = "Porcentaje de Ausentismo Electoral",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
)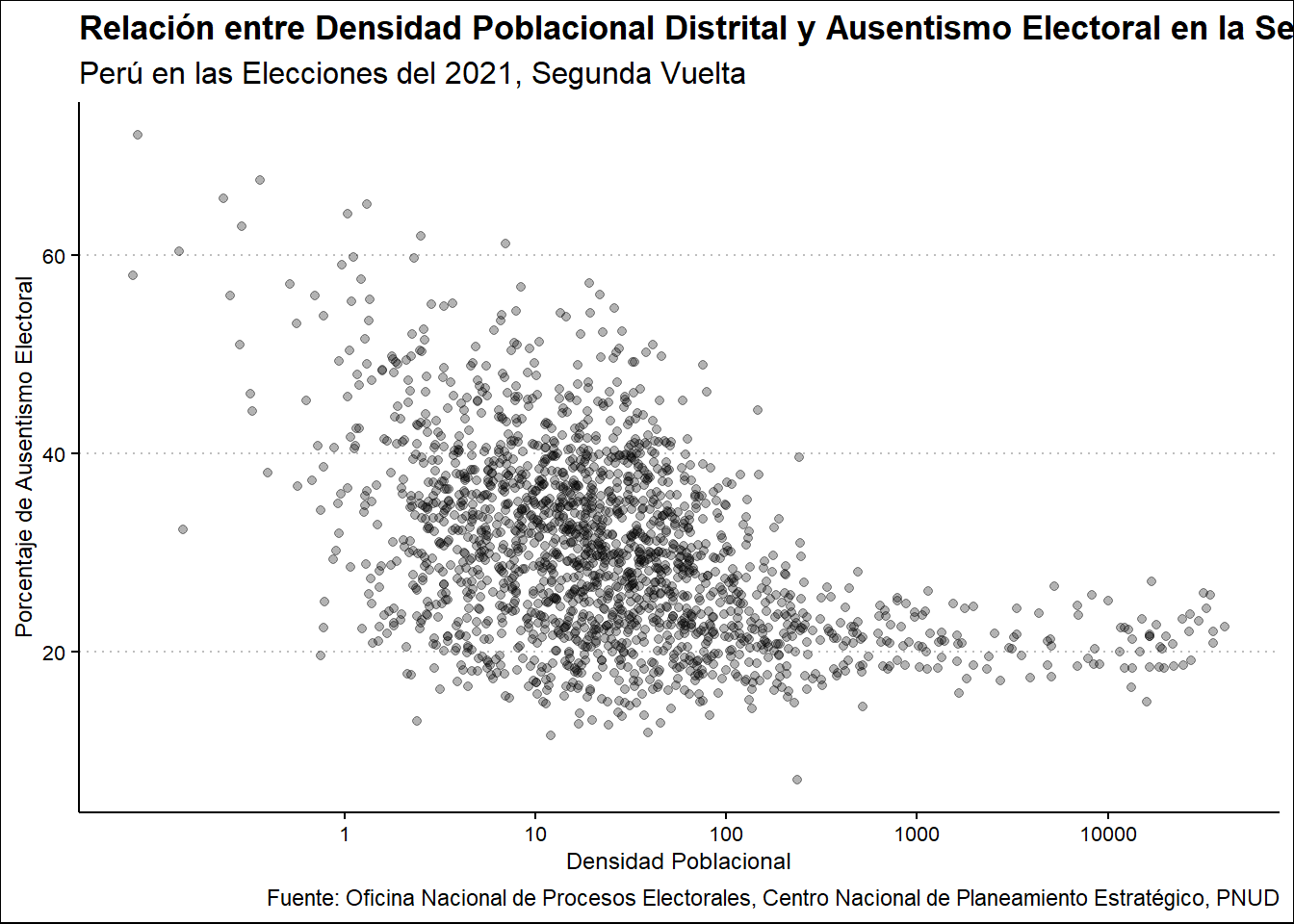
Una menor densidad poblacional tiene una alta dispersión respecto al ausentismo, lo que va reduciendose a medida que se eleva la densidad poblacional, aunque con una relación muy débil.
Ahora procedemos a observar el caso del Porcentaje de Población en Situación de Pobreza.
Ausentismo2021 %>%
select(UBIGEO, PORPOBPOBR, PORAUSENTEV2) %>%
ggplot(aes(PORPOBPOBR, PORAUSENTEV2)) +
geom_point() +
labs(
title = "Relación entre Porcentaje de la Población en Situación de Pobreza y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Porcentaje de la Población en Situación de Pobreza",
y = "Porcentaje de Ausentismo Electoral",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
)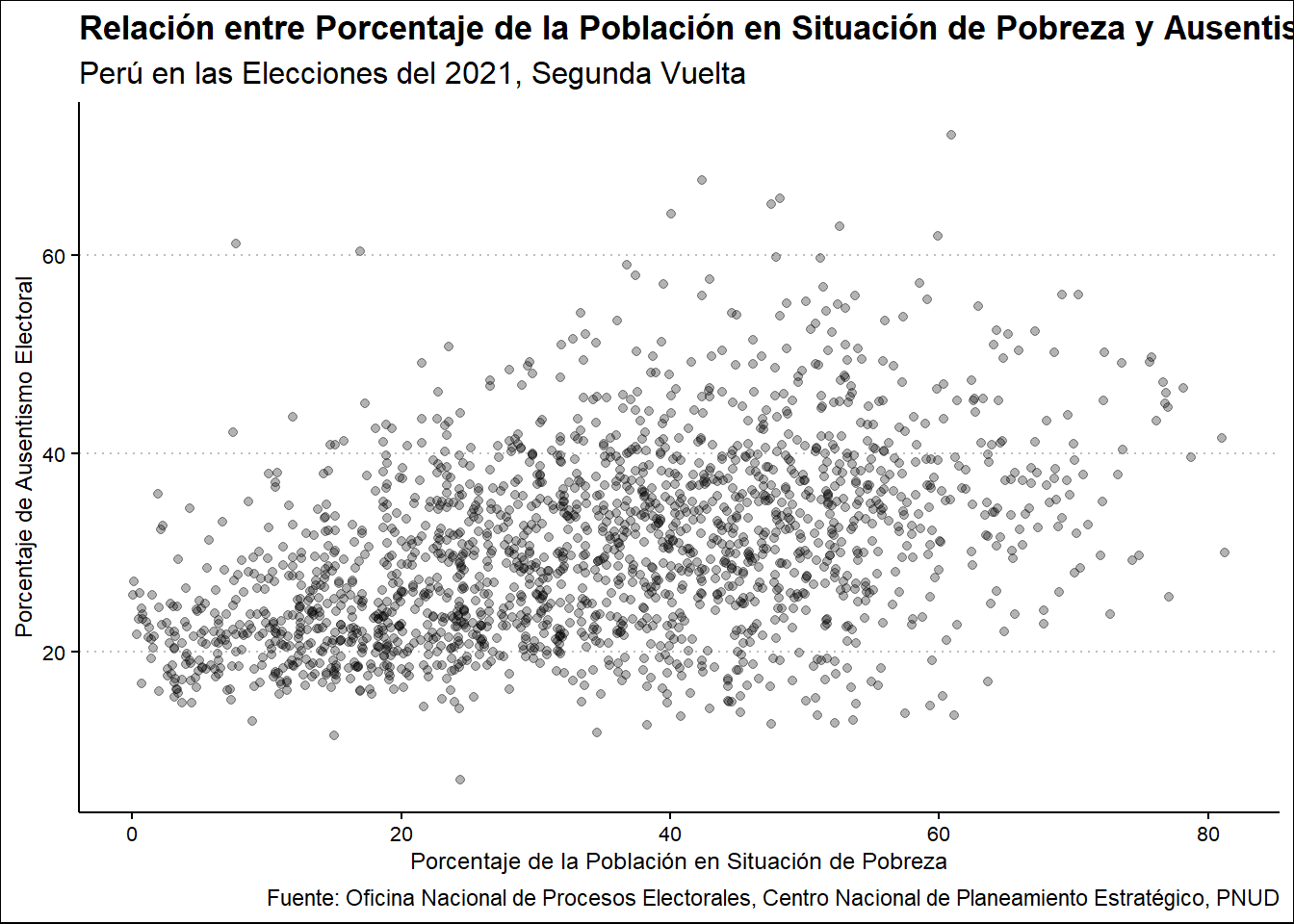
En este caso, hay una relación positiva débil entre el Ausentismo y el Porcentaje de Población en Situación de Pobreza, aunque la dispersión se eleva a medida que el Porcentaje de la Población en Situación de Pobreza.
En el caso de la Población en Situación de Pobreza Extrema, esta tendencia se hace más fuerte.
Ausentismo2021 %>%
select(UBIGEO, PORPOBPOBREX, PORAUSENTEV2) %>%
ggplot(aes(PORPOBPOBREX, PORAUSENTEV2)) +
geom_point() +
labs(
title = "Relación entre Porcentaje de la Población en Situación de Pobreza Extrema y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Población en Situación de Pobreza Extrema",
y = "Porcentaje de Ausentismo Electoral",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
)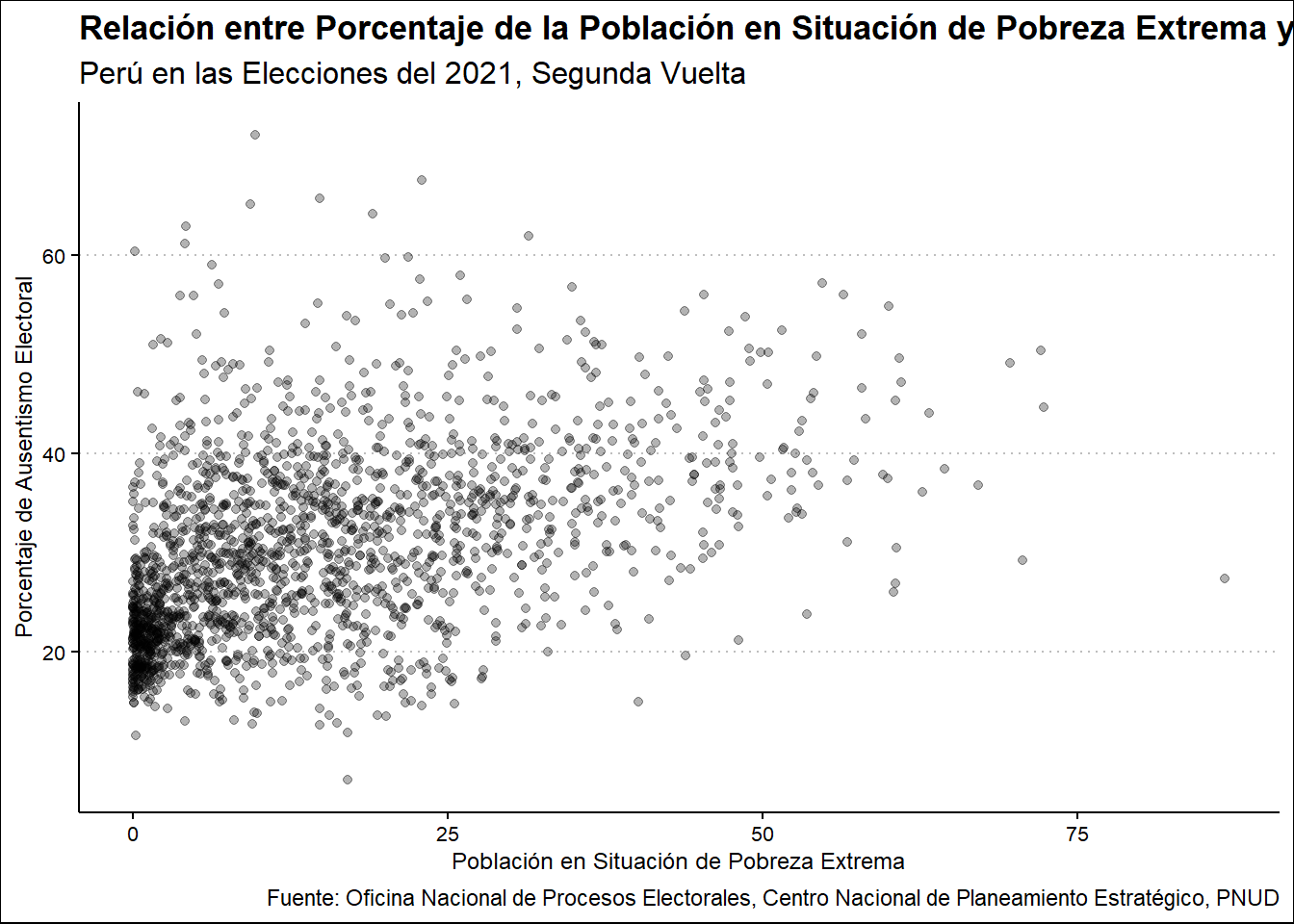
Los casos con menor porcentaje de Población en Situación de Pobreza Extrema se aglomeran en los niveles más bajos de ausentismo y hay una relación más fuerte respecto a la variable anterior, pero, en misma medida, hay una dispersión más pronunciada a medida que este porcentaje aumenta.
Veamos el caso del Presupuesto Devengado per Capita.
Ausentismo2021 %>%
select(UBIGEO, DEVPERCAP2020, PORAUSENTEV2) %>%
ggplot(aes(DEVPERCAP2020, PORAUSENTEV2)) +
scale_x_log10() +
geom_point() +
labs(
title = "Relación entre Presupuesto Devengado per Capita y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Presupuesto Devengado per Capita",
y = "Porcentaje de Ausentismo Electoral",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
) 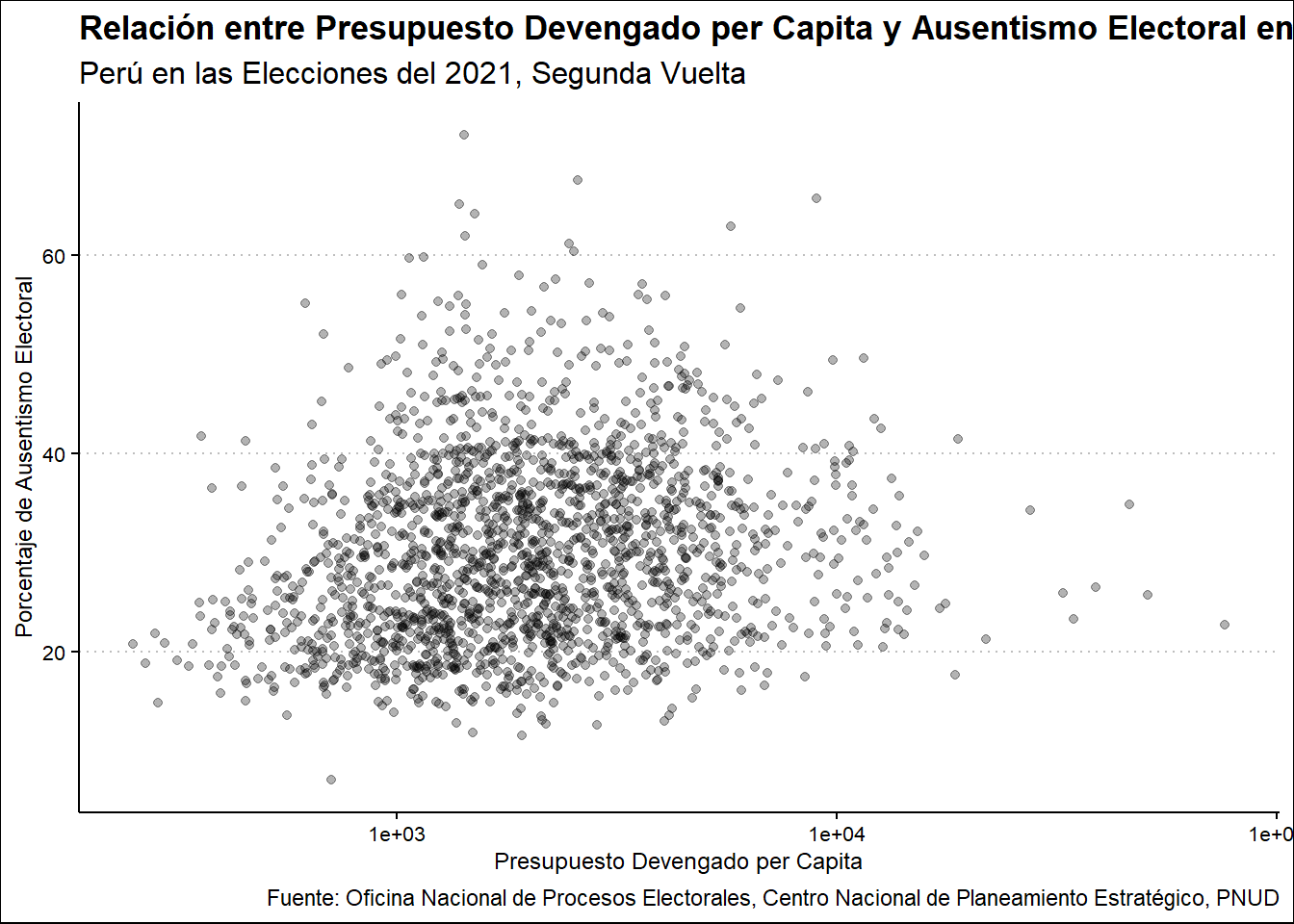
Vemos una pronunciada relación negativa entre ambas variables, concentrándose los casos en el margen del 40% y 20% de ausentismo, y, considerando los outliers, vemos que no se reduce considerablemente el ausentismo a medida que se eleva el presupuesto devengado per capita.
Revisemos el caso del Porcentaje de Población Mayor de 18 años con Secundaria Completa.
Ausentismo2021 %>%
select(UBIGEO, POB18SECOM, PORAUSENTEV2) %>%
ggplot(aes(POB18SECOM, PORAUSENTEV2)) +
geom_point() +
labs(
title = "Relación entre Porcentaje de la Población con Secundaria Completa y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Porcentaje de la Población con Secundaria Completa",
y = "Porcentaje de Ausentismo",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
) 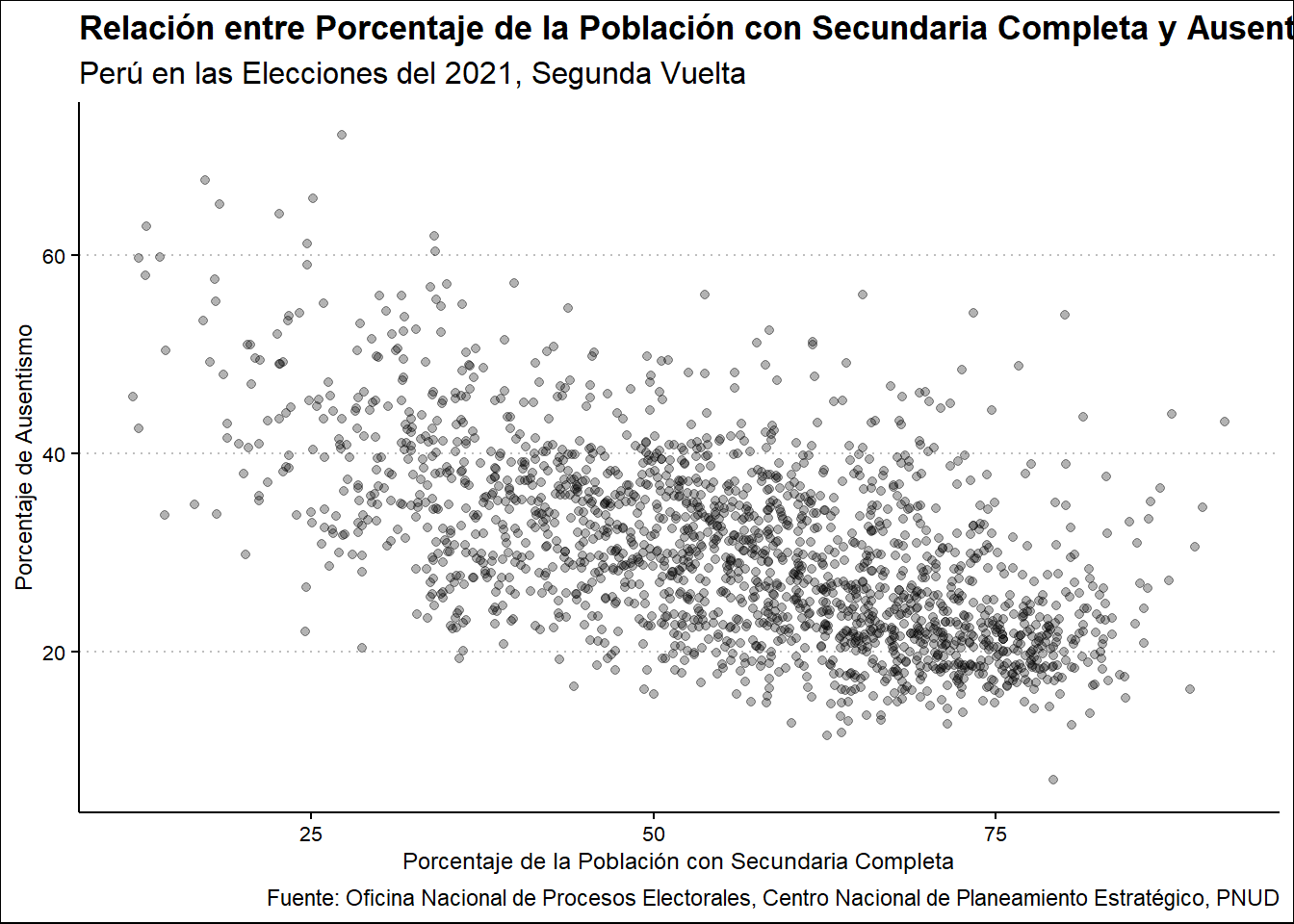
Se detecta una relación negativa entre ambas variables, con una relación medianamente fuerte, evidenciandose una concentración en el 20% de ausentismo. Nuevamente, hay una menor dispersión en la segunda vuelta.
Comparemos el caso del Ingreso Familiar per Capita.
Ausentismo2021 %>%
select(UBIGEO, INGFAMCAP, PORAUSENTEV2) %>%
ggplot(aes(INGFAMCAP, PORAUSENTEV2)) +
geom_point() +
labs(
title = "Relación entre Ingreso Familiar per Capita y Ausentismo Electoral en la Segunda Vuelta",
subtitle = "Perú en las Elecciones del 2021, Segunda Vuelta",
x = "Ingreso Familiar per Capita",
y = "Porcentaje de Ausentismo",
caption = "Fuente: Oficina Nacional de Procesos Electorales, Centro Nacional de Planeamiento Estratégico, PNUD"
) 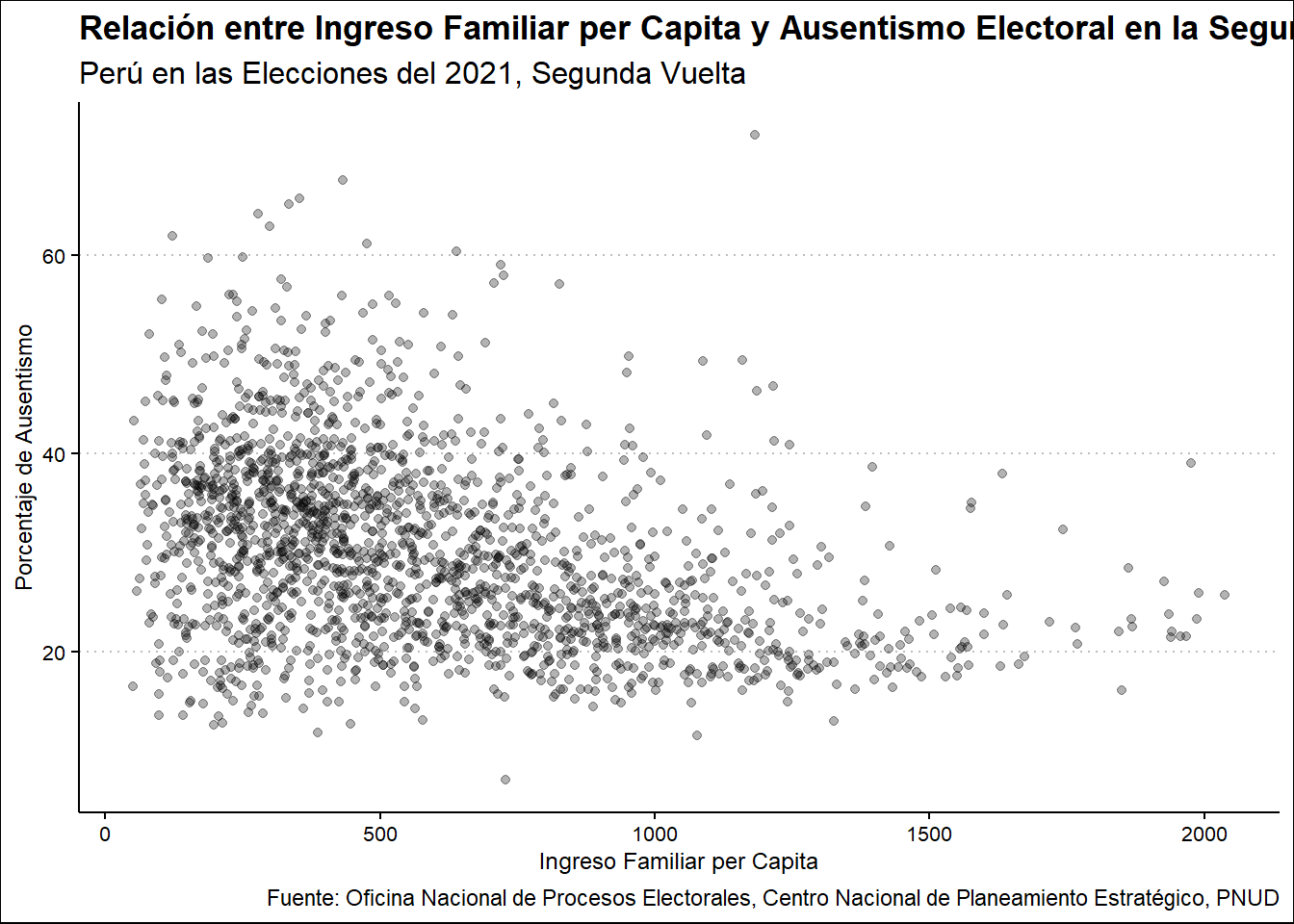
En el caso del Ingreso Familiar per Capita, vemos que los ingresos más bajos se concentran en el margen del 40% y 20% de ausentismo, reduciéndose a medida que aumentan los ingresos, pero hasta los 1500 soles, donde se dispersa y, ligeramente, se revierte la tendencia.
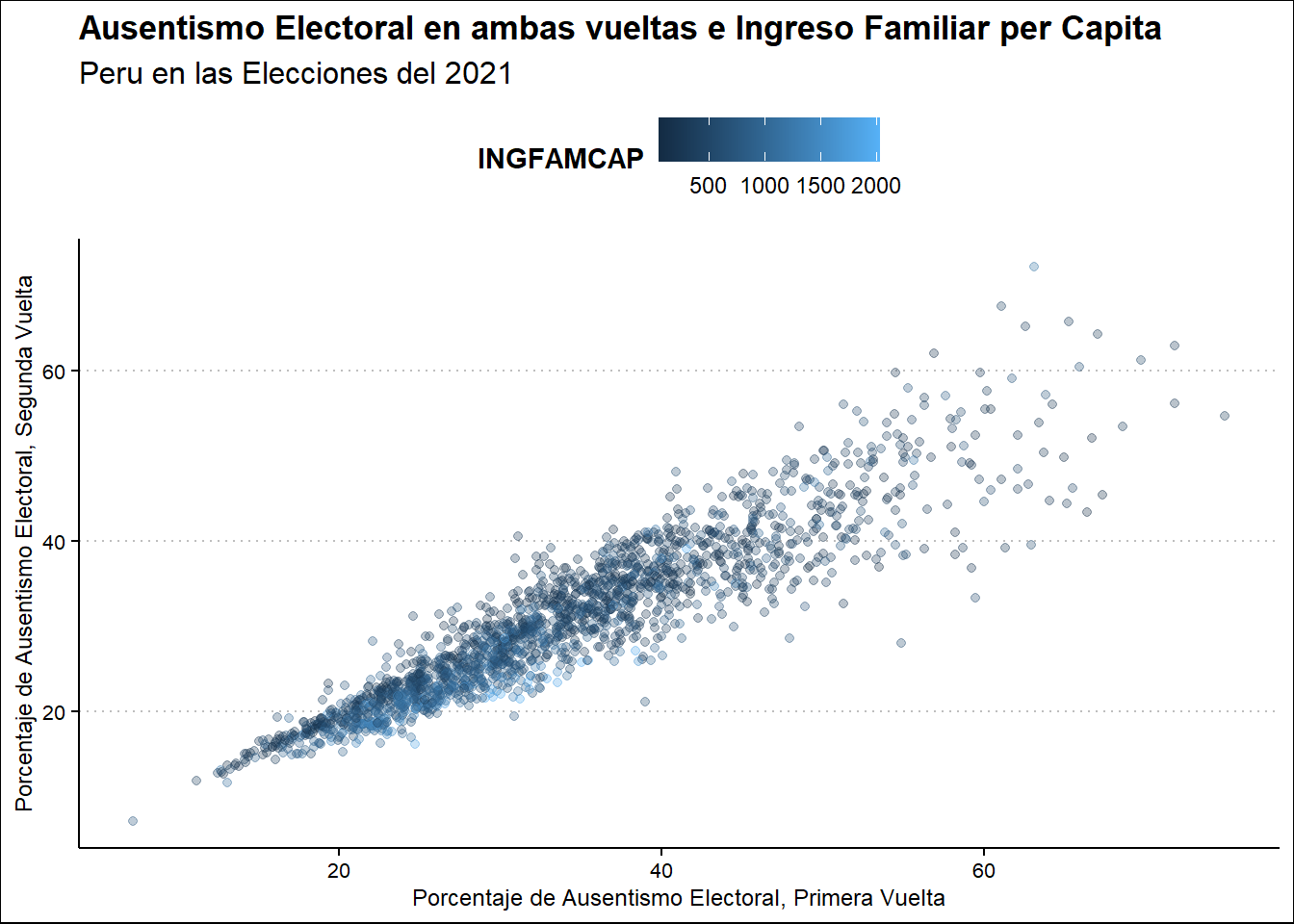
Por último, comparando el ausentismo entre ambas elecciones, es posiblee afirmar que en la segunda vuelta se reduce la dispersión, y el ausentismo en los sectores de menores ingresos.
Ausentismo2021 %>%
select(UBIGEO, PORAUSENTEV1, PORAUSENTEV2, INGFAMCAP) %>%
ggplot(aes(PORAUSENTEV1, PORAUSENTEV2, color = INGFAMCAP)) +
geom_point() +
labs(
title = "Ausentismo Electoral en ambas vueltas e Ingreso Familiar per Capita",
subtitle = "Peru en las Elecciones del 2021",
x = "Porcentaje de Ausentismo Electoral, Primera Vuelta",
y = "Porcentaje de Ausentismo Electoral, Segunda Vuelta",
)
2.5 Conclusiones
Se hipotetizó que la Densidad Poblacional influiría en el Porcentaje de Ausentismo Electoral, demostrándose una gran dispersión en los casos de baja densidad pero un menor ausentismo en los casos de mayor densidad. Asimismo, se comprobó que los indicadores socioeconómicos, como Ingreso Familiar, Población en Situación de Pobreza y Nivel Educativo tenían una influencia importante. Llamó la atención cómo una mayor precariedad (bajo nivel educativo, pobreza, bajos ingresos, baja esperanza de vida) antes que aumentar el ausentismo, dispersaban los casos y dificultaban encontrar una relación.
Aunque un estudio sobre el comportamiento político supondría un estudio más a nivel de individuos, de cada votante, sus apreciaciones, expectativas y actitudes, así como tomar en cuenta por quienes votaron cada uno de estos distritos y vincularlo a las variables sociales que se utilizaron.
Aunque ciertamente es sutil, los sectores con menores ingresos votaron más en la Segunda Vuelta que en la primera. En la entrega anterior, señalé que los sectores más afluentes en Lima Metropolitana tenían los niveles de ausentismo más altos en las Elecciones Extraordinarias del 2020. En este caso, vemos que no hubo un cambio importante en su comportamiento, pero si en los distritos con más carencias, más apáticos en la Primera Vuelta pero aumentando su participación en la Segunda Vuelta.
Aunque se sabe que las localidades más pobres tuvieron una votación mayoritaria hacia Pedro Castillo, el grado de movilización hacia el voto en la Segunda Vuelta nos da un elemento más a considerar en lo que implicaron estas elecciones, partiendo de la población que apoyo a determinadas candidaturas y el cálculo costo-beneficio que supuso este cambio de comportamiento.
Ciertamente el análisis de los factores que llevan al ausentismo electoral deben ser exploradas más allá de gráficos, evaluando más variables que las presentadas, pero esta breve exploración puede iniciar nuevas preguntas que falte realizarse, así como ver el problema en perspectiva histórica.